


Introduction
CVE stands for Common Vulnerabilities and Exposures. It's a system that assigns an ID to publicly known security flaws in software and hardware. CVEs make it easier for researchers, vendors, and users to talk about the same issue using a common reference. Instead of saying “that weird bug in version 2.4.1 of X software,” we can just say “CVE-2024-12345” — much clearer and easier to track.
But just having a list of CVEs isn't enough. We also need a way to match those vulnerabilities to the software and systems we actually run in production. That’s where CPE strings come in.
CPE stands for Common Platform Enumeration. A CPE string tells us exactly which vendor, product, and version a CVE affects. For example, a CPE string like cpe:2.3:a:apache:http_server:2.4.54:*:*:*:*:*:*:* makes it clear that Apache HTTP Server version 2.4.54 is impacted. This is super helpful for vulnerability management tools, vulnerability scanners, and even DevOps workflows to quickly check: Am I affected by a public CVE or not?
The National Institute of Standards and Technology (NIST) maintains a public database called the NVD — the National Vulnerability Database. It tracks all CVEs and also enriches them with metadata, including severity scores (CVSS), attack vectors, and — importantly — CPE strings. Other organizations involved in managing CVEs are called CVE Numbering Authorities (CNAs). They can be software vendors like Microsoft or security companies like Rapid7. These CNAs assign new CVEs and publish them to the CVE list.
The Problem - CPE Gap
Here’s the problem: NVD is lagging behind.
More and more CVEs are being published every day, and while they may appear in the CVE list, many of them are missing detailed information. Most importantly, they're missing the matching CPE strings. This process is called “NVD enrichment” — it's where NIST takes the raw CVE and adds all the useful stuff like CPEs, attack vectors, exploitability metrics, and references. But due to high volume or limited resources (or both), this enrichment is often delayed.
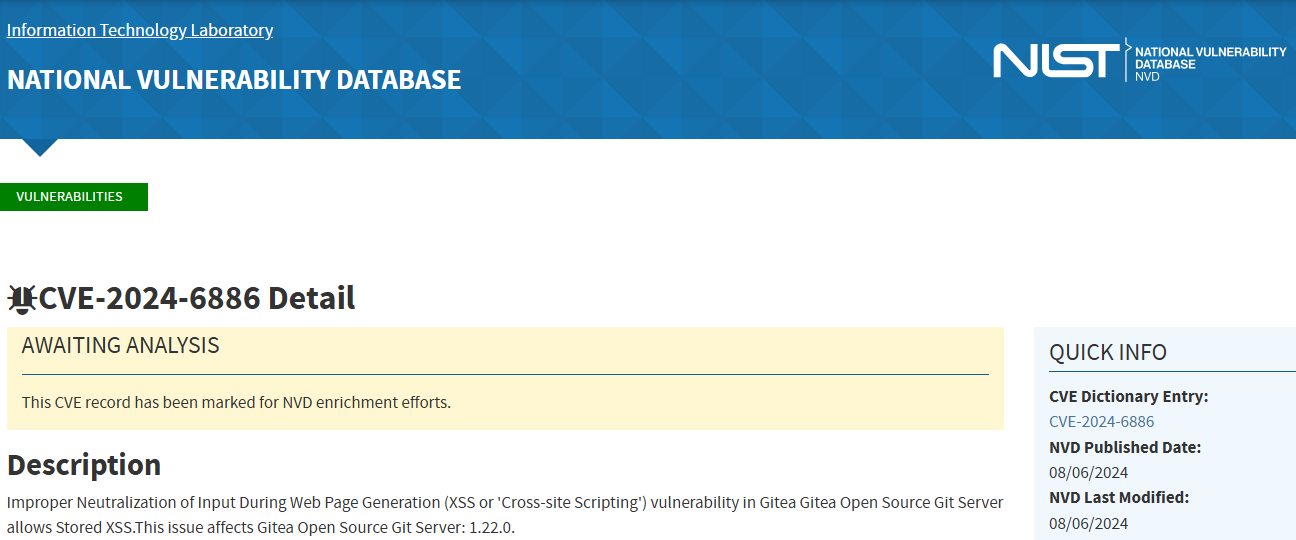
This causes real problems. A CVE without a CPE attached is basically just a headline. We know there's a vulnerability, we may obtain some infos manually from the CVE description but we don’t know exactly what product or version ranges are affected — and that blocks automation.
Vulnerability scanners might skip it, dashboards won’t show it properly, and security teams can’t react fast enough because the data is incomplete. So while the CVE system is great, it’s only really useful when enriched with proper CPEs. Without them, we’re left guessing.
Deep Dive into NVD Database
Now that we understand what CVEs and CPEs are, let’s take a closer look at the National Vulnerability Database (NVD) itself.
NVD is the go-to source for enriched vulnerability data. It takes raw CVEs from the official CVE list and adds extra information like:
- CVSS scores (Common Vulnerability Scoring System)
- CPEs (Common Platform Enumeration)
- KEV (Known Exploited Vulnerability Catalog)
- References to advisories or patches
- Weakness types (like CWE-79 for XSS)
This makes NVD an essential building block for anything related to vulnerability management, automation, dashboards, alerting, or compliance.
Missing CPE Data
The NVD database contains, at the time of writing, around 294,976 CVEs and about 1,412,832 CPE strings. Sounds pretty solid, right?
But here comes the catch: 26,176 CVEs (9%) have no CPE string assigned at all.
That means these vulnerabilities aren’t linked to any known software product. They exist in the database, but we can’t automatically tell what vendor or version is affected — unless we manually dig through vendor advisories or wait for the NVD to do the enrichment work.
Here’s a breakdown of those 26,176 “CPE-missing” CVEs, grouped by the year they were published. I have excluded all CVEs with a Rejected reason: string in the description field.
| Year | CVEs without CPE |
|---|---|
| 2025 | 8,955 |
| 2024 | 14,135 |
| 2023 | 1,909 |
| 2022 | 661 |
| 2021 | 230 |
| 2020 | 72 |
| 2019 | 37 |
| 2018 | 27 |
| 2017 | 8 |
| 2016 | 5 |
| 2015 | 4 |
| 2014 | 3 |
| 2012 | 2 |
| 2004 | 2 |
| 2003 | 2 |
| 2002 | 1 |
| 2001 | 3 |
| 2000 | 3 |
| 1999 | 117 |
As expected, most of the missing CPE data is from recent years — 2024 and 2025 alone account for over 70% of all unmatched CVEs. This clearly shows how much the NVD is currently lagging behind in its enrichment process, especially for newly disclosed vulnerabilities.
Wanna know about these CVEs with missing CPEs? Feel free to download the XLSX file here:
Wrong Enrichment Data
Besides missing CPEs, many other things can go wrong.
For example:
- Referencing a CPE with a non-existent product name:
- cve-2024-45401 referencing the product "stripe-cli", which does not exist. However, the product "stripe_cli" exists and already links to other CVEs.
- Referencing URLs to advisories or patches, which are no URLs at all:
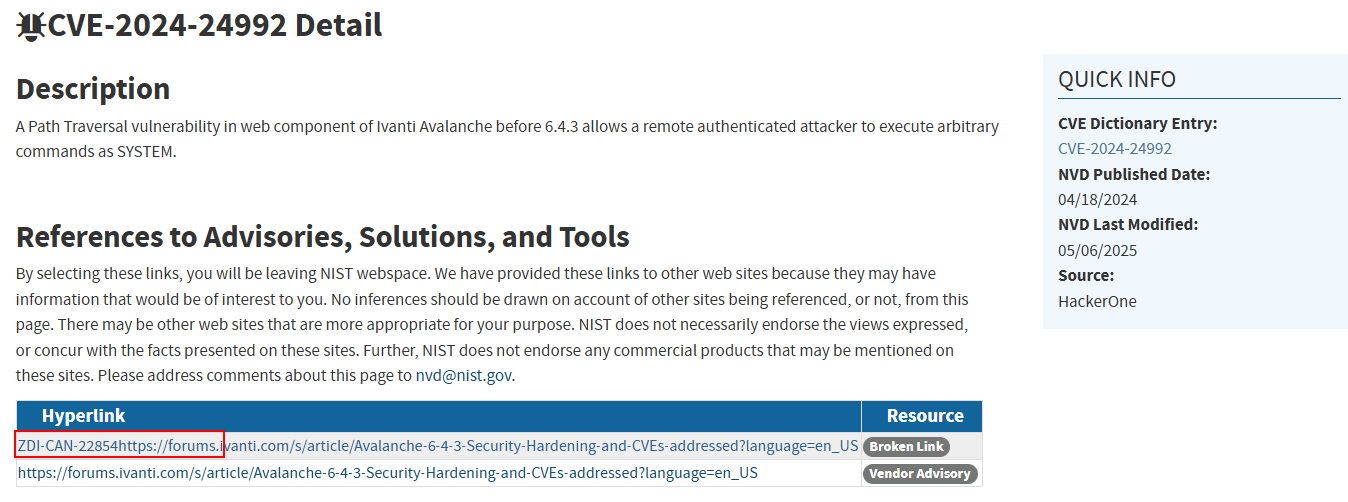
- cve-2023-47124 with a bogus HTTP protocol URL "ttps://www.cloudflare.com/learning/ddos/ddos-attack-tools/slowloris/"
- cve-2024-24992 with a bogus URL "ZDI-CAN-22854https://forums.ivanti.com/"

Political Turmoil
Adding fuel to the fire, recent political decisions have started to hit the CVE system at its core.
In April 2025, it was reported that the Trump administration, under a cost-cutting initiative halted government funding for MITRE, the non-profit that plays a central role in the CVE ecosystem.
MITRE is not only the steward of the CVE system, but also the backbone of many public-private security efforts. Without funding, MITRE would have to deprecate parts of its CVE publication infrastructure, and several teams responsible for vetting and assigning CVEs would either be let go or paused indefinitely.
While the situation looked critical just a few weeks ago, there's good news: MITRE has confirmed that the CVE Program will continue operating.
After a period of uncertainty — with funding paused and layoffs making headlines — MITRE announced that it has secured the necessary support to continue managing and publishing CVEs.
Why This Hurts
The delay in CPE mapping or false enrichments mean:
- Vulnerability scanners miss issues because they rely on CPE-based detection.
- Dashboards show “zero affected systems” even when that’s not true.
- Security teams are left in the dark about what actually needs patching.
- Risk assessments are incomplete, because CVSS scores and product mappings aren’t available.
It’s a pretty big deal, especially if you're trying to build automation or alerts based on CVE feeds.
Alternative Data Sources
Other players in the security space have stepped-in to help fill the gap. Some of them run their own enrichment pipelines or even do manual mapping of affected products and versions.
Here are a few worth checking out:
🔍 CVE Details
CVE Details has been around for years. They offer a searchable web interface that pulls in CVE info and often includes product, vendor, and version data even when NVD hasn’t published it yet.
Their enrichment isn’t perfect, but it often includes references and patch info earlier than the official feed. I recommend using CVEDetails!
🧠 Snyk
Snyk is mainly focused on developer security and web/cloud ecosystems (npm, pip, Docker, etc.), but they do a great job of mapping web-related software and open-source libraries to their associated CVEs.
Their database is highly curated, which can be far more useful than NVD alone. I recommend using Snyk!
🔥VulnDB
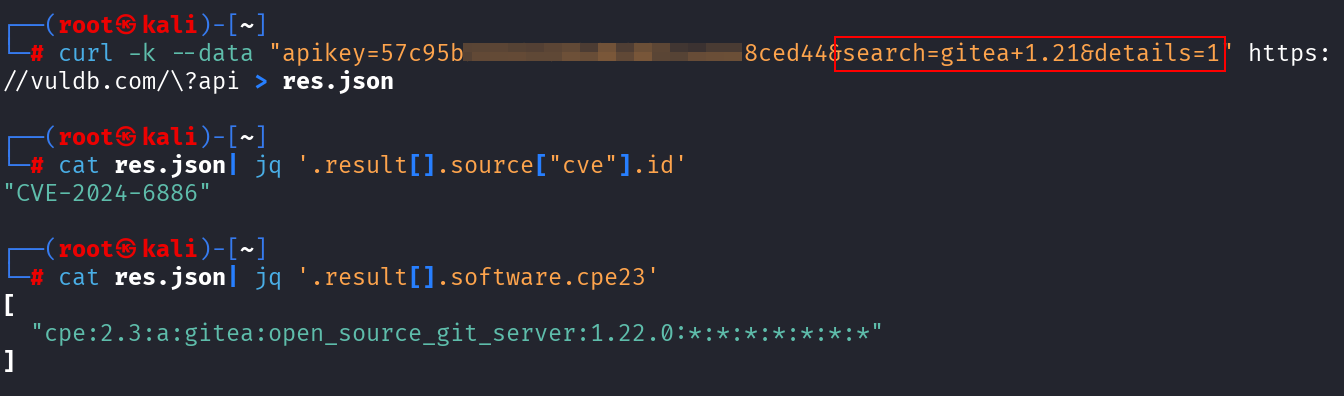
VulDB is an officially certified CVE Numbering Authority (CNA) by MITRE and Authorized Data Publisher (ADP) by NIST NVD. If you use their API, you will find CPE strings for nearly all unmatched CVEs from above. They do a great work enriching CVE data.
In my opinion, one of the best services to use. They offer 50 daily API credits for free and some other paid credit/rate options.
🤖 Cybersecurity-help.cz
Another (partially paid) third party service offering vulnerability data and enrichments. Sometimes works but often fails to find CVEs and to match products plus versions. Nothing special and too pricey API for what it is.
🌐 VulnCheck
VulnCheck takes a different approach. It is based on the NVD database but applies a custom enrichment and calls it NVD++. What seemingly sounds great, still isn't perfect. A simple search for CVE vulnerabilites for "Vaultwarden" returns nothing. Fun fact, there are various CVEs available. Just not linked to a CPE by NVD. So Vulncheck's enrichment seems not to be complete.
🫠 Vulnerability-Lookup
Vulnerability-Lookup facilitates quick correlation of vulnerabilities from various sources, independent of vulnerability IDs, and streamlines the management of Coordinated Vulnerability Disclosure (CVD). It is also a collaborative platform where users can comment on security advisories and create bundles.
What sounds great, is not really usable atm. The API is broken and does not help in finding vulnerabilities by CPE string.
😂 European Vulnerability Database
The European Union Agency for Cybersecurity (ENISA) has unveiled the European Vulnerability Database (EUVD), an initiative under the NIS2 Directive aimed at enhancing digital security across the EU. The database serves as a centralized repository offering aggregated and actionable information on cybersecurity vulnerabilities affecting ICT products and services.
Their web service provides a search by ID (CVE/EUVD) or text. No mapping or linking to CPEs with vendors, products and version strings. Therefore, unusable.
Moreover, the FAQ states that the EUVD is based on Vulnerability-Lookup. A non-usable service already mentioned above.
The EUVD service retrieves its data by querying the Vulnerability-Lookup collection, enriches the data, and assigns a unique EUVD identifier (on top of existing identifiers such as CVE) to each vulnerability record.
So What Can You Do About It?
There is an easy solution — at least in theory.
We just need the CVE data to be properly enriched with CPE strings and metadata. And that’s exactly what the NVD - or all the different CNAs - are supposed to do. But as we’ve seen, the current backlog and processing delays make this unreliable — especially for newer CVEs.
Unfortunately, it seems we and many third-party services are still dependent on NVD for official enrichment. That’s the main bottleneck. No matter how good your scanner or pipeline is, if the data from NVD is missing the CPE, there’s nothing to match against.
If you are really dependent on latest CVE/CPE data, I would recommend VulnDB's API.
Own Approach
I first stumbled into this whole topic while working on my own CVE API backend and web service — basically a tool to easily search and filter CVEs by product, version, or vendor.
At first, I assumed it would be straightforward: pull data from the NVD database or JSON feeds, parse it, and match product versions using CPEs. But pretty quickly I hit a wall. I was wondering why certain products showed zero results — even though I knew for a fact they had published vulnerabilities.
After digging deeper, it turned out the issue wasn’t with my code or logic. The CVEs existed, but they were just missing CPE mappings in the NVD data. That one missing link made the whole correlation and concept fall apart. I spent hours scratching my head, thinking my filters were broken — when in reality, the data just wasn’t there yet.
That’s when I realized how much of our tooling relies on complete and enriched CVE data — and to be honest, it’s nowhere near good enough right now.












Discussion